| Сообщения без ответов | Активные темы |
Текущее время: 19 июн 2026, 17:39 |
|
Часовой пояс: UTC + 3 часа [ Летнее время ] |
|
|
Страница 1 из 21 |
[ Сообщений: 412 ] | На страницу 1, 2, 3, 4, 5 ... 21 След. |
| Версия для печати | Пред. тема | След. тема |
Очень низкоуровневый эмулятор 6502 / NES
| Автор | Сообщение |
|---|---|
|
|
|
 Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Созрел для тактовой эмуляции 6502, буду тут складировать свои раскопки
 Источник всех картинок Visual 6502 : http://visual6502.org Но так как их визуальный симулятор не позволяет сделать вменяемую логическую схему (нет ни виасов, ни обозначения транзисторов), я решил разбирать 6502 по кусочкам самостоятельно. Дополнительные источники : Схема 6502 от Дональда Хенсона : http://www.weihenstephan.org/~michaste/ ... 2/6502.jpg Реверсинг 6502 от Берегнея Балазса (кажется так) : http://www.downloads.reactivemicro.com/ ... gineering/ -- 19 июн 2012, 14:52 -- API эмулятора Управление виртуальным процессором осуществляется путем изменения сигнальных переменных контекста. Сигнальные переменные соответствуют реальным выводам микросхемы оригинального процессора. Контекст процессора 6502 : Код: typedef struct context_6502 { // Внутреннее состояние // ...... // Входные сигналы int RDY, IRQ, NMI, RES, SO; // Выходные сигналы int SYNC, RW; // Шины unsigned short ADDR; unsigned char DATA; } context_6502; Управление выполнением процессора Код: void step_6502_phi1 ( context_6502 * cpu ); // assume PHI1 high void step_6502_phi2 ( context_6502 * cpu ); // assume PHI2 high Зачем сделано два вызова ? Внутренняя архитектура 6502 разделяет входной такт на два "подтакта" - PHI1 и PHI2, сдвинутые немного по фазе, относительно входного сигнала PHI При этом эти тактовые импульсы выдаются наружу управляющему устройству. Логика следующая : Высокий уровень PHI1 : адресная шина и шина данных доступна для чтения внешними устройствами Высокий уровень PHI2 : внешним устройствам разрешено писать в шину данных Таким образом задается синхронизация чтения-записи между внешней шиной и внутренними шинами процессора Поэтому фактически работа с 6502 происходит полутактами. Графически это можно представить так : Код: ____ PHI0 |____| |____ ____ ___ PHI1 _| |____| _ ____ PHI2 |____| |__ Как исполнять виртуальный процессор ? Костяк эмулятора выглядит следующим образом : 1. Установить входные сигналы перед фазой PHI1, считать значения шины адреса и данных 2. Выполнить step_6502_phi1 3. Установить входные сигналы перед фазой PHI2, установить значение шины данных 4. Выполнить step_6502_phi2 5. Синхронизировать время исполнения с реальным временем 6. Выполнить сервисные функции эмулятора (отобразить видео, проиграть аудио, отладка и пр.) 7. Перейти на 1 -- 19 июн 2012, 15:03 -- Исследование #NMI. Решил начать с чего-нибудь попроще. На картинке представлен пин #NMI.  Условные обозначения : 1. Выход всей схемы идёт через этот полисиликоновый провод и далее поступает в "контроллер прерываний". Вход соответственно с самой площадки пина #NMI. 2. Крепление "земли". Питание подается на металл, которых находится в правом нижнем углу. 3. Тут видимо предусмотрен виас для "Not connected" пина. Зачем, непонятно, да и для анализа этой схемы не нужно. Напомню основные принципы NMOS : - Металл расположенный поверх всего чипа используется в основном для питания и отвода на землю. Пересекается со схемой он в так называемых "виасах" - их можно распознать как круглые точки. Сам металл - такие золотисто-желтые жилы. - под металлом находится диффузия, вытравленная на непроводящей подложке. - в местах пересечения полисиликона (более светлые полоски) и диффузии формируется полевой транзистор (MOSFET). При этом полисиликон образует его базу, а диффузия - сток и исток. - места соединения полисиликона и диффузии (например для замыкания базы на исток) называются "зарытыми контактами". На картинке такой контакт обозначен кружком. Обычно это используется для транзисторов с открытым истоком (open-drain mosfets). - Open-drain транзисторы являются по сути дела резисторами подтяжки. Для анализа логической схемы их можно игнорировать. Разберемся в логике работы NMI, а точнее что будет на выходе 1, при разных состояниях входа #NMI. ШАГ 1. Создание цветовой схемы. Вначале в Photoshop отделим овец от волков, или как там.. Чтобы было четко понятно - где металл, а где диффузия и полисиликон.  Цветовые обозначения : Металл Красный - питание, зеленым - земля. Синий - межсоединения. Диффузия Не стал разделять диффузию по уровням. Цвет - желтый. Полисиликон Фиолетовый Виасы и зарытые контакты Виасы - черные кружки, зарытые контакты - оранжевые. ШАГ 2. Создание транзисторной схемы. После получения цветовой схемы нам нужно выявить транзисторы. Эквивалентная транзисторная схема выглядит следующим образом :  Превращаем open-drain трансы в резисторы и получаем :  ШАГ 3. Создание логической схемы. Из полученной транзисторной схемы восстановим логическую схему. Восстанавливать особо нечего, полученная схема - это по-просту элемент NOT :  Из описания прерываний 6502: Цитата: The processor's non-maskable interrupt (NMI) input is edge sensitive, which means that if the source of an NMI holds the line low, further NMIs after the first are effectively disabled. The simultaneous assertion of the NMI (non-maskable) and IRQ (maskable) hardware interrupt lines causes IRQ to be ignored. However, if the IRQ line remains asserted after the servicing of the NMI, the processor will immediately respond to IRQ, as IRQ is level sensitive. Thus a sort of built-in interrupt priority was established in the 6502 design. NMI срабатывает по перепаду уровней. Так, если #NMI имеет низкий уровень, то следующие перепады уровня не вызывают NMI. При одновременном срабатывании NMI и IRQ - IRQ игнорируется. Но если IRQ будет иметь высокий уровень, после обработки NMI, то процессор ответит на IRQ, так как IRQ срабатывает по уровню. Таким образом в 6502 есть своего рода приоритет прерываний. Данный блок схемы запускает логику обработки NMI, когда #NMI имеет низкий уровень. (для рисования схем использовался http://www.gliffy.com ) -- 19 июн 2012, 22:46 -- Кое что посложнее Логика работы пинов RDY и RESET. Цветная схема :  Без металла :  Сам этот кусочек, относительно всего чипа :  Последний раз редактировалось org 21 июл 2012, 22:48, всего редактировалось 1 раз. |
|
|
|
 Зарегистрирован: 23 июл 2007, 19:37 Сообщения: 401 Откуда: Мытищи |
Очень интересно. Quietust сделал симулятор 2А03 на основе Visual6502 и послойных снимков 2А03,
а вот с PPU проект заглох: фотографии сделаны, но организатор сказал, что заниматься слоями не будет. Вот так выглядит delayering Что касается 2А03/2С02: Я правильно понимаю, что нельзя расшифровать логику чипа, не сняв обязательно все его слои? Общей фотографии кристалла после декапа недостаточно и никакая кропотливая расшифровка не поможет? _________________ Nestopia 1.37/1.40 Fixed |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Под слоем металла трудно различить диффузию и пути полисиликона. Но при достаточном опыте можно "угадать" как они расположены.
Поэтому PPU и заглох, потому что декап сделали, но металл ещё не стравили. Ядро 6502, которое находится в NES APU и MOS 6502, который я сейчас изучаю, за исключением некоторых "хирургических вмешательств" (виасы "вникуда"), как выразился Quietust почти не отличается. Потихоньку, полегоньку разберу весь процессор 6502, а потом найду отличия с 2A03, чтобы окончательно закрыть эту страницу эмуляции NES. Ну ближе к теме... Цветная схема RDY.  Эта схема имеет 2 выхода (а может один из них - вход). Первый провод идёт куда-то во внутренности ALU (кажется), а второй - на PLA ROM декодера инструкций. Провод, помеченный красным кружком, который прыгает туда сюда с металла на полисиликон к схеме отношения не имеет. Отдельно помечены тактовые импульсы PHI1 и PHI2, которые задают логику работы схемы для первого и второго полутактов. Напоминаю, что хотя пирог внешне выглядит "слоеным", но пересечение ингридиентов происходит исключительно в местах черных точек (виасов). Цветная схема RESET.  Схема имеет один выход, который имеет общепринятое название Reset0. Аналогично RDY, помечены тактовые управляющие линии PHI1 и PHI2. -- 20 июн 2012, 12:09 -- Транзисторная схема RDY   В это схеме на самом деле 2 схемы. Как оказалось - 2 провода это выходы. Первый выход Условно называется "Not Ready". Логика работы такая : Код: if ( PHI2 == 1 ) Not Ready = ~RDY; else Not Ready = 0; Из описания пина RDY : Если внешнее устройство хочет чтобы процессор "подождал", оно должно выставить RDY низкий уровень. В этом режиме процессор будет "ждать", когда RDY станет опять высокого уровня. Однако в фазе записи (PHI1) процессор не будет ждать, даже если RDY низкого уровня. Второй выход Второй выход идёт на линию PLA ROM "op-branch-done". Условно я назвал его "BranchReady". Логика работы: Код: if (PHI2) BranchReady = 1; else BranchReady = 0; Таким образом обработка условного перехода начинается только в фазе чтения (PHI2) процессора. Эта часть схемы не зависит от пина RDY. Видимо просто разработчики решили запихнуть эту логику в блок "READY CONTROL". -- 20 июн 2012, 13:59 -- Транзисторная схема RES  Много pullup-ов. Судя по описаниям, где-то здесь прячется триггер Шмитта (для фильтрации дребезга контактов)... Но в нашей идеальной схеме это и не важно. Вся схема работает только в первой фазе работы процессора (PHI1) (на выходе стоит отсекающий вентиль), во время PHI2 выход Reset0 = TRUE. Логика следующая : Код: if (PHI2 == 1) Reset0 = 1; else Reset0 = RES; |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Схема генерации тайминга декодера
Используется для задания очередности выполнения инструкций. Результат работы - выдача в декодер инструкции номера "такта" - T2, T3, T4 или T5. Из описаний известно, что номер "такта" получается путём сдвигания единички влево : Код: T5 T4 T3 T2 T1 T0 первый такт 0 0 0 0 0 1 T5 T4 T3 T2 T1 T0 второй такт 0 0 0 0 1 0 и так далее Значит эта схема должна напоминать регистр сдвига.  Цветная схема :   На второй картинке показаны шланги, с помощью которых этот блок общается с внешним миром. Основные - это конечно t5 - t2, они идут непосредственно в декодер. Смысл остальных проводов пока не очень понятен. -- 21 июн 2012, 17:25 -- Транзисторная схема TIMING CONTROL Как оказалось в цветную схему попал кусок из другой части, похоже контроллера прерываний ")  Управляющие шланги : R - что-то вроде "Ready" NR - инвертированный в схеме Ready, то есть "Not Ready" ) 1 - пока не понятно что такое, похоже на Reset или Halt, будет понятно после разбора логики работы 2 - это Sync (из схемы Балазса) Ф1 и Ф2 фазовые сигналы режимов процессора. -- 21 июн 2012, 21:06 -- После непродолжительного анализа стало понятно что схема состоит из 4х частей :  -- 22 июн 2012, 10:17 -- Немного подчистил схему и кое-где были перепутаны названия (Ready / NotReady ).   шланг 1 - это как и предполагалось - сброс. Назвал его TimReset. Кстати положительный уровень на выходах t5 ... t2 означет что инструкция декодера НЕ будет срабатывать. То есть, чтобы определенная инструкция сработала например на такте T2, его уровень должен быть низким. |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Instruction Register (IR)
  С этой схемой особых проблем не возникло. IR представляет собой набор flip-flops. Этот регистр хранит код инструкции на протяжении всего процесса декодирования. Загрузка регистра производится из Predecode Register (PD), когда вход fetch высокого уровня. Установленный pdX.clearIR очищает соотв. бит IR или выставляет его в 1, если линия низкого уровня. Отдельно стоит упомянуть о третьей входной линии в декодер PLA, которая называется irline3. Если приглядеться то на вход подаются все биты IR + инвертированные версии битов (для сравнения), однако вместо IR1 выдается комбинация битов IR0 и IR1: irline3 = IR0 | IR1; отдельно цветом помечена схема логического ИЛИ для irline3. Пока неизвестно зачем это делается. Также на схеме присутствует "наскальная графика" MOS |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Декодер инструкций (PLA)
Расположение на чипе :  Для удобства я перевернул картинку цветной схемы набок :  Транзисторную схему рисовать не буду, потому что тут и так всё понятно. На вход декодера поступает регистр инструкции (IR), в котором содержится код текущей инструкции (при этом бит0 и бит1 заведены на одну линию) + его инвертированный вариант (/IR), а также текущий такт (T0-T5). Дополнительный вход BranchReady идёт с логики RDY. Как происходит декодирование ? Если хотя бы одна линия пересекается с диффузией, то заряд стекает на землю и линия "не срабатывает". Поэтому логика каждого входа (присоединенного к диффузии) такая: Если НЕ(ВХОД_1) И НЕ(ВХОД_2) И НЕ(ВХОД_N) -> линия срабатывает. Ну и дополнительно для перехода линия срабатывает только в том случае, если BranchReady = 1. |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Шина данных
Отхватил приличный кусок чипа  Полная картина:  D-пин:  Data latch:   Data latch - это временное хранилище информации с шины данных. Логика процессора посредством управляющих линий потом распихивает эти данные по внутренним шинам и регистрам. EDIT: Нашёл ошибку - неучтенный контакт. Исправленная схема:  ЛОГИКА РАБОТЫ Логика работы достаточно хитрая. Рассмотрим отдельно чтение в шину данных и отдельно запись. Чтение шины данных Для начала нужно ознакомиться с общей схемой :  Как видно входы шины данных при чтении идут на защелку (Data latch), при этом tri-state buffer должен быть "отсоединен". Немного по поводу tri-state буффера. Этот буфер может иметь три значения - питание, земля и "отсоединен". Питание подается когда нужно записать в шину данных "1", земля подключается когда в шину данных нужно записать "0". А при чтении tri-state буффер "отсоединяется" от шины, чтобы не записывать туда ни "1", ни "0". Tri-state отсоединен когда R/W = 1. Графическая схема чтения "1" с шины данных :  Возникает проблема : первый полутакт процессор находится в режиме записи. Поэтому первый полутакт чтения (Ф1) происходит чтение мусора из Data latch (ну точнее не мусора, а предыдущего значения). Во время второго полутакта (Ф2) данные с шины данных попадают на Data latch (который устроен как DRAM - заряд хранится на "плавающей" базе). И только во время третьего полутакта уже следующего машинного цикла новые данные поступают на внутренние шины процессора. На какие именно шины подавать данные задаются управляющими сигналами : DL/ADL, DL/ADH и DL/DB. Данные могут поступать параллельно на все три шины. Отдельно стоит отметить что во время Ф2 все шины "подзаряжаются", то есть имеют значение 0xFF. Код: PHI1: if (DL_ADL) ADL = DL; if (DL_ADH) ADH = DL; if (DL_DB) DB = DL; PHI2: DL = DATA; ADL = ADH = DB = 0xFF; Запись в шину данных С записью попроще :  Данные поступают в регистр DOR во время Ф1 и выдаются наружу, как во время Ф1, так и во время Ф2. Акт записи регулируется только включением и отключением tri-state буфера. На картинке показано как выход регистра DOR, проходящий через инвертор взаимоисключающей логикой выбирает путь записи "1" в шину данных. Соответственно при записи "0" выбрался бы другой путь. На самом деле на схеме провод R/W идёт не прямо с пина R/W, это внутренняя линия. Не исключено что во время Ф1 эта линия отключает tri-state, как это нарисовано на схеме Дональда, поэтому я добавлю в псевдокод только фазу Ф2. Также необходимо учесть, что всё что записывается в шину данных, сразу попадает обратно в Data latch. Код: PHI1/PHI2: if (PHI1) DOR = DB; if (RW == 0 && PHI2) DATA = DOR; Совмещенный псевдокод логики работы ВСЕЙ схемы : Код: PHI1: if (DL_ADL) ADL = DL; if (DL_ADH) ADH = DL; if (DL_DB) DB = DL; DOR = DB; PHI2: if (RW == 0) DATA = DOR; DL = DATA; ADL = ADH = DB = 0xFF; Последний раз редактировалось org 03 июл 2012, 21:40, всего редактировалось 3 раз(а). |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Address pin
Решил запечатлеть как происходит процесс реверсинга на видео : Часть 1 : подготовка. Из двух исходных гигантских изображений вырезаем нужный кусок и сохраняем в фотошопе. Предварительно делается отцентровка верхнего слоя над нижним. Часть 2 : цветная схема. Начинаем с диффузии (желтая), потом металл (земля - зеленая, питалово - красное, межсоединения - синим), затем контакты (черные с металлом, оранжевые - диффузия с полисиликоном) и наконец - полисиликон (фиолетовый). В этой части я лажанулся, стал рисовать полисиликон не в том слое )) Пришлось немного потупить и переделать. Часть 3 : транзисторная схема. Доооолго обдумывал за что же зацепиться, потом дело пошло на лад ) Транзисторная схема адресного пина :  Логика работы  Схема содержит бит регистра ABH. Запись произодится в фазе Ф1, при установленном контрольном сигнале ADH/ABH. В фазе Ф2 выход берется из статической защелки регистра ABH. Как известно работа 6502 поделена на 2 фазы (Ф1 и Ф2). Ф1 - "фаза записи", Ф2 - "фаза чтения". Фаза записи (Ф1) ADH7 = 1  ADH7 = 0  Фаза чтения (Ф2) Если в фазе записи ADH7 был High:  Если в фазе записи ADH7 был Low:  Как эмулировать Всё просто. step_6502_phi1: if (ADH_ABH) ABH = ADH; ADDR = (ABH << 8 ) | ABL; step_6502_phi2: ADDR = (ABH << 8 ) | ABL; -- 03 июл 2012, 13:11 -- Вывод SYNC Цветная схема :  смайликом помечено место не подсоединенной площадки, расследование тут : http://visual6502.org/wiki/index.php?ti ... ync_and_BA вторая ветка внутреннего сигнала sync уходит в контроллер тайминга (см. где-то выше была схема) Транзисторная схема :  Логика работы простая: SYNC = sync   (усилительные каскады) |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Random Logic
Основная часть процессора. Направляет результат работы декодера (130 линий) на соотв. внутренние шины и регистры процессора. Только начал делать схему, покажу что получается :  Логика работы  |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Регистры X, Y, S
Показывать всю схему и рисовать регистры полностью нет необходимости. Слева от регистров находится адресная шина (логику которой я уже разобрал). Структура сверху, напоминающая "расческу" - это контрольные выводы с рандомной логики. Именно они указывают что делать с регистрами и шинами. К примеру по команде "Y/SB" - регистр Y будет размещён на внутренней шине SB. Ну и так далее. Таких "микрокоманд" довольно много и какую из них исполнить выбирается рандомной логикой, в зависимости от кода инструкции и текущего цикла. Ну это позже, а сейчас регистры. Цветная схема одного бита каждого из регистров (бита 0):  Структура регулярная и просто повторяется 8 раз (8 бит). Транзисторная схема:  Зеленым я пометил места, где находятся защелки регистров ("плавающие" базы). Логика работы простая. В зависимости от микрокоманд - загрузить регистр с шины SB, либо поместить его туда. Регистр S также дополнительно может быть помещен на шину ADL, а также "рециркулирован" сам на себя (для следующего такта). Операции с регистрами происходят в Ф1, а во время Ф2 происходит их "хранение". Причем на протяжении Ф2 шина SB = 0xFF. Код: PHI1: if ( Y/SB ) SB = Y; if ( SB/Y ) Y = SB; if ( X/SB ) SB = X; if ( SB/X ) X = SB; if ( S/ADL) ADL = S; if ( S/SB ) SB = S; if ( SB/S ) S = SB; if ( S/S ) S = S; PHI2: SB = 0xFF; -- 06 июл 2012, 14:26 -- Predecode Register Эта часть нужна для предварительного анализа кода инструкции, а также как временный буфер, для загрузки в регистр IR. На вход в PD поступают шланги с шины данных (напрямую), которые записываются в регистр PD при Ф2. На выходе PD - данные регистра, либо нули, если на вход PD подается сигнал "clearIR" (очистить IR). В верхней части находится комбинационная схема, которая имеет два выхода в рандомную логику. Точный смысл выходов пока не понятен, но они имеют смысл по типу "только инструкции, которые занимают 2 цикла" или что-то вроде того. Нужно смотреть для чего именно используются эти 2 выхода. Цветная схема :  Транзисторная :  Входы шины данных перепутаны из-за того что их так удобней подводить к схеме. |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Program Counter
Счетчик инструкций состоит из двух половинок PCH (верхняя) и PCL (нижняя). Графические и транзисторные схемы : PCL   PCH   Общая диаграмма Д.Хенсона:  Ну теперь немного о логике работы. Управляющий вход IPC запускает инкрементер. В целях оптимизации (спасибо ребятам с 6502.org, просвятили), каждый нечетный бит работает с инверсной логикой, чтобы уменьшить propagation delay в линии переноса разряда. Для эмулятора это не важно. Нижняя половинка выдает PCLC на PCH при переносе. Верхняя половинка разделена ещё на 2 части, при этом нижняя часть передает перенос через PCHC. Как уже говорилось, во время Ф2 все шины (DB, ADH, ADL) имеют значение 0xFF. Кусочки этой логики разбросаны тут и там, их я не буду приводить на схемах. Работа инкрементера происходит в Ф1. Результаты работы записываются в Ф2. Код: PHI1: if (PCL/PCL) PCLS = PCL; if (ADL/PCL) PCLS = ADL; if (PCL/PCL && ADL/PCL) PCLS = PCL & ADL; if (PCH/PCH) PCHS = PCH; if (ADH/PCH) PCHS = ADH; if (PCH/PCH && ADH/PCH) PCHS = PCH & ADH; if (IPC) PCLS++; if (PCLS == 0) PCHS++; if (PCL/DB) DB = PCL; if (PCL/ADL) ADL = PCL; if (PCH/DB) DB = PCH; if (PCH/ADH) ADH = PCH; PHI2: PCL = PCLS; PCH = PCHS; ADH = ADL = DB = 0xFF -- 08 июл 2012, 22:21 -- Потихоньку подобрался к ALU :  Заодно набросаю тут основные функциональные элементы 6502: - Timing control (+) - Programmable Logic Array (decoder) (+) - Instruction register (+) - Interrupt and reset logic - Predecode logic (+) - Random logic - Registers X,Y,S (+) - Program Counter (+) - ALU - Address bus control (+) - Data bus control (+) Плюсиками пометил наличие транзисторных схем. |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Восстановил цветные схемы рандомной логики и ALU
А также декодировал PLA: Код: A 01: 000101100000100100000 100XX100 TX STY 02: 000000010110001000100 XXX100X1 T3 OP ind, Y 03: 000000011010001001000 XXX110X1 T2 OP abs, Y 04: 010100011001100100000 1X001000 T0 DEY INY 05: 010101011010100100000 10011000 T0 TYA 06: 010110000001100100000 1100XX00 T0 CPY INY B 01: 000000100010000001000 XXX1X1XX T2 OP zpg, X/Y & OP abs, X/Y 02: 000001000000100010000 10XXXX1X TX LDX STX A<->X S<->X 03: 000000010101001001000 XXX000X1 T2 OP ind, X 04: 010101011001100010000 1000101X T0 TXA 05: 010110011001100010000 1100101X T0 DEX 06: 011010000001100100000 1110XX00 T0 CPX INX 07: 000101000000100010000 100XXX1X TX STX TXA TXS 08: 010101011010100010000 1001101X T0 TXS 09: 011001000000100010000 101XXX1X T0 LDX TAX TSX 10: 000110011001100010000 1100101X TX DEX 11: 001010011001100100000 11101000 TX INX 12: 011001011010100010000 1011101X T0 TSX 13: 000100011001100100000 1X001000 TX DEY INY 14: 011001100000100100000 101XX100 T0 LDY 15: 011001000001100100000 1010XX00 T0 LDY TAY C 01: 011001010101010100000 00100000 T0 JSR 02: 000101010101010100001 00000000 T5 BRK 03: 010100011001010100000 0X001000 T0 Push 04: 001010010101010100010 01100000 T4 RTS 05: 001000011001010100100 0X101000 T3 Pull 06: 000110010101010100001 01000000 T5 RTI 07: 001010000000010010000 011XXX1X TX ROR 08: 000000000000000001000 XXXXXXXX T2 T2 ANY 09: 010110000000011000000 010XXXX1 T0 EOR 10: 000010101001010100000 01X01100 TX JMP 11: 000000101001000001000 XXX011XX T2 RIGHT R ODD 12: 010101000000011000000 000XXXX1 T0 ORA 13: 000000000100000001000 XXXX0XXX T2 LEFT ALL 14: 010000000000000000000 XXXXXXXX T0 T0 ANY 15: 000000010001010101000 0XX0X000 T2 BRK JSR RTI RTS Push/pull 16: 000000000001010100100 0XX0XX00 T3 BRK JSR RTI RTS Push/pull + BIT JMP D 01: 000001010101010100010 00X00000 T4 BRK JSR 02: 000110010101010100010 01000000 T4 RTI 03: 000000010101001000100 XXX000X1 T3 OP X, ind 04: 000000010110001000010 XXX100X1 T4 OP ind, Y 05: 000000010110001001000 XXX100X1 T2 OP ind, Y 06: 000000001010000000100 XXX11XXX T3 RIGHT ODD 07: 001000011001010100000 0X101000 TX Pull 08: 001010000000100010000 111XXX1X TX INC NOP 09: 000000010101001000010 XXX000X1 T4 OP X, ind 10: 000000010110001000100 XXX100X1 T3 OP ind, Y 11: 000010010101010100000 01X00000 TX RTI RTS 12: 001001010101010101000 00100000 T2 JSR 13: 010010000001100100000 11X0XX00 T0 CPY CPX INY INX 14: 010110000000101000000 110XXXX1 T0 CMP 15: 011010000000101000000 111XXXX1 T0 SBC 16: 011010000000001000000 X11XXXX1 T0 ADC SBC 17: 001001000000010010000 001XXX1X TX ROL E 01: 000010101001010100100 01X01100 T3 JMP 02: 000001000000010010000 00XXXX1X TX ASL ROL 03: 001001010101010100001 00100000 T5 JSR 04: 000000010001010101000 0XX0X000 T2 BRK JSR RTI RTS Push/pull 05: 010101011010100100000 10011000 T0 TYA 06: 100000000000011000000 0XXXXXX1 T1 UPPER ODD 07: 101010000000001000000 X11XXXX1 T1 ADC SBC 08: 100000011001010010000 0XX0101X T1 ASL ROL LSR ROR 09: 010101011001100010000 1000101X T0 TXA 10: 011010011001010100000 01101000 T0 PLA 11: 011001000000101000000 101XXXX1 T0 LDA 12: 010000000000001000000 XXXXXXX1 T0 ALL ODD 13: 011001011001100100000 10101000 T0 TAY 14: 010000011001010010000 0XX0101X T0 ASL ROL LSR ROR 15: 011001011001100010000 1010101X T0 TAX 16: 011001100001010100000 0010X100 T0 BIT 17: 011001000000011000000 001XXXX1 T0 AND 18: 000000001010000000010 XXX11XXX T4 RIGHT ODD 19: 000000010110001000001 XXX100X1 T5 OP ind, Y F 01: 010000010110000100000 XXX10000 T0 <- Branch + BranchReady line 02: 000110011001010101000 01001000 T2 PHA 03: 010010011001010010000 01X0101X T0 LSR ROR 04: 000010000000010010000 01XXXX1X TX LSR ROR 05: 000101010101010101000 00000000 T2 BRK 06: 001001010101010100100 00100000 T3 JSR 07: 000101000000101000000 100XXXX1 TX STA 08: 000000010110000101000 XXX10000 T2 Branch 09: 000000100100000001000 XXXX01XX T2 zero page 10: 000000010100001001000 XXXX00X1 T2 ALU indirect 11: 000000001000000001000 XXXX1XXX T2 RIGHT ALL 12: 001010010101010100001 01100000 T5 RTS 13: 000000000000000000010 XXXXXXXX T4 T4 ANY 14: 000000000000000000100 XXXXXXXX T3 T3 ANY 15: 010100010101010100000 0X000000 T0 BRK RTI 16: 010010101001010100000 01X01100 T0 JMP 17: 000000010101001000001 XXX000X1 T5 OP X, ind 18: 000000001000000000100 XXXX1XXX T3 RIGHT ALL G 01: 000000010110001000010 XXX100X1 T4 OP ind, Y 02: 000000001010000000100 XXX11XXX T3 RIGHT ODD 03: 000000010110000100100 XXX10000 T3 Branch 04: 000100010101010100000 0X000000 TX BRK RTI 05: 001001010101010100000 00100000 TX JSR 06: 000010101001010100000 01X01100 TX JMP 07: 000000011001010100000 0XX01000 TX Push/pull 08: 000101000000100000000 100XXXXX TX 80-9F 09: 000101010101010100010 00000000 T4 BRK 10: 000101011001010101000 00001000 T2 PHP 11: 000100011001010101000 0X001000 T2 Push 12: 000010101001010100010 01X01100 T4 JMP 13: 000010010101010100001 01X00000 T5 RTI RTS 14: 001001010101010100001 00100000 T5 JSR H 01: 000110101001010101000 01001100 T2 JMP 02: 001000011001010100100 0X101000 T3 Pull 03: 000010000000000010000 X1XXXX1X TX LSR ROR DEC INC DEX NOP (4x4 bottom right) 04: 000001000000010010000 00XXXX1X TX ASL ROL 05: 010010011010010100000 01X11000 T0 CLI SEI 06: 101001100001010100000 0010X100 T1 BIT 07: 010001011010010100000 00X11000 T0 CLC SEC 08: 000000100110000000100 XXX101XX T3 OP zpg, X 09: 101010000000001000000 X11XXXX1 T1 ADC SBC 10: 011001100001010100000 0010X100 T0 BIT 11: 011001011001010100000 00101000 T0 PLP 12: 000110010101010100010 01000000 T4 RTI 13: 100110000000101000000 110XXXX1 T1 CMP 14: 100010101001100100000 11X01100 T1 CPY CPX 15: 100001011001010010000 00X0101X T1 ASL ROL 16: 100010000101100100000 11X00X00 T1 CPY CPX K KX: 000000011001010100000 0XX01000 TX Not actually line. Controls K09 to except push/pull opcodes ---> 01: 010010011010100100000 11X11000 T0 CLD SED 02: 000001000000000000000 X0XXXXXX TX 00-3F 80-BF 03: 000000101001000000100 XXX011XX T3 RIGHT R EVEN 04: 000000100101000001000 XXX001XX T2 LEFT R EVEN 05: 000000010100001000001 XXXX00X1 T5 ALU indirect 06: 0000000010100?0000010 XXX11XXX T4 RIGHT ODD (? is actually 0, but strange.. 0XX11XXX T4 if supposed to be vias there) 07: 000000000000010000000 0XXXXXXX TX UPPER ALL 08: 001001011010100100000 10111000 TX CLV 09: 000000011000000...... XXXX10X0 TX All flags + DEY TAY INY INX - 0XX01000 <--- controlled by KX Осталось разобрать и понять работу рандомной логики и собрать все части вместе, чтобы получить готовый 6502. Неужели я хоть что-то до конца доведу )))) Вложения:
ALU_col_nomet.png [ 418.92 КБ | Просмотров: 434295 ] ALU_col.png [ 599.12 КБ | Просмотров: 434295 ] LOGIC_col_nomet.png [ 830.58 КБ | Просмотров: 434295 ] LOGIC_col.png [ 1.09 МБ | Просмотров: 434295 ] |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Я скоро транзисторам срать начну.. но этот проект доведу до ума
На картинке почти готовая схема рандомной логики. Осталось добавить несколько блоков и настроить связи. В целом логика работы понятна, и даже продумано как это будет эмулироваться. На вход рандомной логики подается: - 130 линий с декодера. - несколько линий (пока не смотрел) из логики обработчика прерываний - CARRY OUT из ALU (разряд переноса), который потом помещается в регистр флагов - бит IR5 из регистра инструкции (для регистра флагов) На выходе : - 6 линий текущего T-шага инструкции для декодера - 2 линии с PREDECODE, определяющие класс инструкции - линия "fetch" для регистра инструкций (получить код инструкции из predecode-регистра) - "Драйверы" - линии для управления регистрами, шинами и ALU - CARRY IN для ALU (разряд переноса) из регистра флагов - Внутренняя линия sync выводится наружу с одноименного пина, через усилительные каскады. - линия R/W Также рандомная логика подключена к 8 линиям внутренней шины DB, для обмена с регистром флагов (P). Как эмулировать Эмулировать "пробегание" 130 линий путем сравнения по маске с IR будет долго и нецелесообразно. Вместо этого будет использоваться look-up таблица на 256 значений и 256 обработчиков. Результаты работы будут заноситься в DRIVE-регистр по битовой маске, наример: DRIVEREG |= DRIVE_ANDS; После работы рандомной логики происходит вызов операций, по маске из DRIVE-регистра : if ( DRIVEREG & DRIVE_ANDS) { сделать операцию AND на ALU } итп. -- 20 июл 2012, 00:25 -- Ещё прогресс по ALU. ALU input drivers : /DB/ADD (inverted DB -> B input) DB/ADD (DB -> B input) ADL/ADD (ADL -> B input) SB/ADD (SB -> A input) 0/ADD (0 -> A input) ORS (logical or) SRS (shift right) ANDS (logical and) EORS (logical xor) I/ADDC (carry in) SUMS (arithmetic sum) DAA (decimal addition adjust) ADD/SB7 (adder result -> SB7) ADD/SB06 (adder result -> SB0-6) ADD/ADL (adder result -> ADL) DSA (decimal subtract adjust) SB/DB (SB <-> DB) SB/AC (SB -> accumulator) AC/SB (accumulator -> SB) AC/DB (accumulator -> DB) SB/ADH (SB -> ADH) 0/ADH0 (0 -> ADH0) 0/ADH17 (0 -> ADH1-7) ALU outputs : AVR (overflow out) ACR (carry out) Работа его тоже в целом понятна, нужно только распутать логику работы DAA/DSA. Вложения:
ALU_wip2.png [ 732.1 КБ | Просмотров: 434217 ] LOGIC_wip2.png [ 1.73 МБ | Просмотров: 434236 ] |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Начал предварительные работы над APU, отрассировал землю, питалово и отделил ненужные куски (регион для проверки тех. процессов в правом верхнем углу и ядро 6502).
На первый взгляд APU довольно простой - одни счетчики да регистры сдвига. Очень много регулярных структур, над которыми можно проводить процесс Ctrl+C -> Ctrl+V Качество картинки конечно отстой, но разобрать детали можно, хотя и с трудом.Теперь я уверен, что мы сможем получить полностью дискретный (aka cycle-accurate) 2A03. Также попробовал немного потыркаться с PPU, но имеющиеся изображения отвратительного качества, что-либо разобрать невозможно. Вложения:
APU_wip.png [ 524.42 КБ | Просмотров: 434165 ] PPU_wip.png [ 974.13 КБ | Просмотров: 434165 ] |
|
|
|
|
|
Насколько твои изыскания соответствуют этому доку?
|
|
|
|
|
Зарегистрирован: 23 июл 2007, 19:37 Сообщения: 401 Откуда: Мытищи |
В фотках ППУ столько мусора, что они непригодны для использования.
_________________ Nestopia 1.37/1.40 Fixed |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
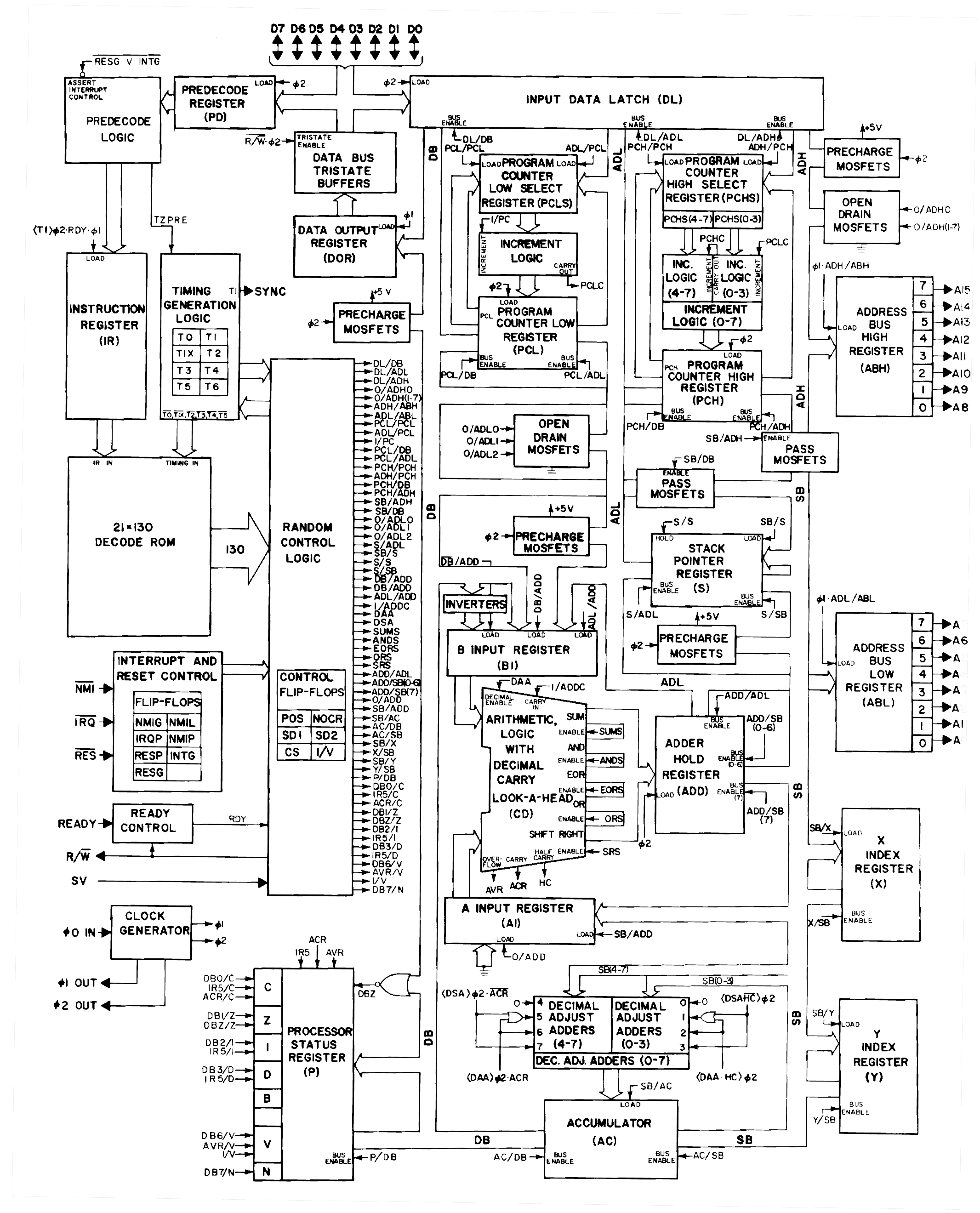
Цитата: Насколько твои изыскания соответствуют этому доку? Это схема Балазса, о которой я писал в 1м посте. Я точно не сверялся, но в целом ключевые части там присутствуют. Сбивает с толку его нотация "R1x1" итп, вообще не понятно. -- 23 июл 2012, 18:51 -- Моск процессора - ALU. Полная транзисторная схема, но пока ещё не анализировал логику работы. Вложения:
ALU_trans.png [ 965.32 КБ | Просмотров: 434046 ] |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
На visual6502 появились фотки NTSC PPU хорошего качества. На них хорошо видно полисиликон и относительно хорошо диффузию.
Я решил не ждать, пока знакомый HWM-а расплавит чипы, которые ему послал EvgS и начал трассировать PPU. Потом скорректирую проблемные места, как будут готовы фотки со снятым слоем металла. С 6502 тоже есть подвижки, но они пока на форуме 6502.org и не относятся к NES (BCD-коррекция). Очень актуальным стал вопрос о создании..... эмулятора телевизора Ведь вывод PPU - это композитный видео-сигнал.Вложения:
wip1.png [ 843.63 КБ | Просмотров: 433775 ] |
|
|
|
|
|
Чел отписал, что уже в ближайшем будущем начнет фотать чипсы. а так как у него там автоматические пъезоэлектричесике мотиваторы, то фотки должны получиться ровные и качественные. А вообще, мне PPU интересен как схема, буду внимательно следить за изысканиями.
 |
|
|
|
|
Зарегистрирован: 24 июл 2007, 10:41 Сообщения: 575 |
Я тем временем проштудировал устройство NTSC-сигнала и как PPU генерирует цвета. Весьма впечатлен насколько там всё сложно (и одновременно просто) устроено )
Самое интересное - это как картинка "дребезжит" на границах цветов (частота сэмплирования пикселей отличается от частоты сэмплирования поднесущей цвета). Ещё случайно наткнулся на изыскания HWM-a на форуме nesdev, особенно порадовали фотки осциллограмм вспышки цветности и вертикальной синхронизации. По ним можно будет искуственно ухудшить эмулируемый video out (шумы и RC-фильтрация сигнала) Единственное что я пока не понял - каким же образом телевизор осуществляет вертикальную синхронизацию.. ведь сигнал может "начаться" с любого места. Где в этом случае рисовать картинку (как позиционированы лучи). Нигде в инете не могу найти как работает последовательность сигналов при вертикальной синхронизации. Эмуляцию телевизора тоже продумал, буду пробовать делать субпиксельный рендеринг, имитируя решетку кинескопа и расположение люминофора. -- 01 авг 2012, 22:45 -- Провел небольшой эксперимент как будет выглядеть картинка на симуляторе кинескопа. Я сделал масочный субпиксельный рендеринг, по маске : x G x R x B R x B x G x виртуальное NTSC поле в 483 строки, шириной в 640 зерен я заполнил рандомными сканлайнами, шириной 256 пикселей. отдельно попробовал делать в цвете и отдельно в черно-белом варианте. впечатления двоякие. с одной стороны в палитре NES оно может и будет неплохо смотреться (надо попробовать), но такое ощущение что чего-то не хватает.. может субпиксельной фильтрации, а может "маскированные" субпиксели не должны быть 100% черного цвета, а тоже должны немного светиться ? Вложения:
tv1.png [ 281.92 КБ | Просмотров: 433708 ] tv2.png [ 40.14 КБ | Просмотров: 433708 ] bw1.png [ 163.1 КБ | Просмотров: 433708 ] bw2.png [ 61.25 КБ | Просмотров: 433708 ] |
{kind=link}
|
|
Страница 1 из 21 |
[ Сообщений: 412 ] | На страницу 1, 2, 3, 4, 5 ... 21 След. |
|
Часовой пояс: UTC + 3 часа [ Летнее время ] |
Кто сейчас на конференции |
Сейчас этот форум просматривают: нет зарегистрированных пользователей и гости: 6 |
| Вы не можете начинать темы Вы не можете отвечать на сообщения Вы не можете редактировать свои сообщения Вы не можете удалять свои сообщения Вы не можете добавлять вложения |